The Cost of Simplicity: Understanding OS Abstraction through Device Drivers
The Hidden Side of Simplicity Link to heading
Before I dove deep into Operating Systems in graduate school, I experimented with Embedded Linux by controlling an LED on a Raspberry Pi. Even though fiddling with a breadboard was a bit tedious, the code itself was deceptively simple. One line of Python was all it took:
|
|
Back then, I didn’t think much beyond that line. But through my research into system software, I’ve realized that behind this simple command lies a massive abstraction layer represented by System Calls and Device Drivers. Implementing this from scratch in the kernel requires hundreds of lines of code.
Interestingly, in a bare-metal environment like Arduino, this complexity doesn’t exist. So, why is LED control so “difficult” on an OS? And why did this complexity evolve in the first place?
The Essence of a Device Driver: The OS is the “Problem” Link to heading
A Device Driver is code that allows the OS to control hardware. While we often define it simply as “hardware access code,” that misses the point. The complexity of a driver stems less from the hardware itself and more from the structural requirements of the OS environment.
A modern OS environment has three fundamental characteristics:
- Multitasking: Dozens of processes run concurrently.
- Protection: Mechanisms must prevent a buggy process from crashing other processes or the entire system.
- Abstraction: A unified interface is required to control diverse devices.
These requirements necessitate the split between Kernel Space and User Space. Applications run in user space and cannot directly access hardware. Whether it’s reading a JSON file, sending a network packet, or lighting an LED, the application must “request” a privileged entity to do it.
We call this request a System Call. Much like a REST API in web development, the Kernel exposes an interface. When an application triggers a system call, the CPU switches to kernel mode, executes a predefined handler, and performs the hardware access safely.
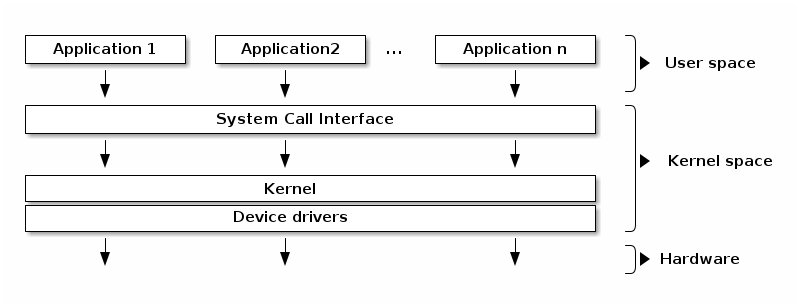
Figure 1: System Call Flow from User Space to Device Driver
While this flow varies by kernel type, I am assuming a Monolithic Kernel like Linux for this discussion.
The Kernel itself doesn’t inherently know how to talk to every SSD, GPU, or NPU. Hardware manufacturers must provide the “manual”—this is the Device Driver. To keep things standardized, Linux exposes these drivers through the file system.
You’ve likely heard the phrase “Everything is a file.” When you install an NVIDIA driver, the GPU appears as /dev/nvidia0. You can then use standard commands like open() and read() (which are system calls) to interact with the GPU. This abstraction is what allows complex hardware to be managed through a familiar interface.
This interface is exactly what Figure 1 illustrates. When your application makes a request—whether it’s turning on an LED, reading from a disk, or sending network data—that request crosses the System Call Interface boundary. The CPU transitions from user mode to kernel mode, routes the request through the appropriate Device Driver, and finally executes the low-level hardware operation. The beauty of this design is that your application remains blissfully unaware of these details; it simply writes to /dev/led as if it were a regular file.
Real-World Implementation: Beyond the Python Script Link to heading
To control an LED at the system level, as demonstrated earlier, we actually need to write two programs: the Device Driver (the bridge) and the Application (the user).
A basic LED driver structure in C looks like this:
|
|
Why so much “boilerplate”?
copy_from_user(): Since User Space and Kernel Space use different virtual memory address spaces, the kernel cannot simply dereference a user-space pointer. We must explicitly copy the data for safety.spin_lock(): Because the OS is a multitasking environment, two processes might try to toggle the LED simultaneously. Without a lock, the hardware state becomes unpredictable.
Once the driver is registered, the “Application” can be as simple as a shell script:
|
|
Through this shell script, we can observe the LED turning on or blinking.
The Complexity of the Asynchronous World: Interrupts Link to heading
The example above covers synchronous tasks (the process initiates the action). But hardware is often asynchronous. Think of a keyboard or a network card; the hardware tells the CPU when an event happens. This is an Interrupt.
In an OS scheduling dozens of processes, we cannot have one process “polling” the hardware (looping constantly to check for updates), as this wastes CPU cycles. Instead, the process goes to sleep, and an interrupt “wakes” it up.
If we add a button to our LED circuit to toggle the state, we need an Interrupt Handler:
|
|
Notice spin_lock_irqsave(). We must disable interrupts while holding the lock. Why is this necessary? Consider the following scenario:
Interrupt handling is managed by the CPU across multiple concurrent events—network packets arriving, keyboard/mouse input, timer interrupts for task switching, and more. If led_write() holds the lock using a regular spin_lock() when the button interrupt fires, the interrupt handler will wait for the lock to be released. However, as mentioned earlier, all interrupt handlers share the same interrupt context, and particularly, timer interrupts are needed to enable process switching. Since the interrupt handler is now stuck waiting for the lock and cannot complete, process switching becomes impossible. Conversely, the process holding the lock in led_write() cannot complete and release the lock without being able to switch back—this is a classic deadlock.
Therefore, led_write() must use spin_lock_irqsave() to disable interrupts before acquiring the lock, and device driver code must be written even more carefully when interrupts are involved.
Conclusion: Complexity is the Foundation of Orchestration Link to heading
The complexity of a device driver isn’t “bloat.” It is the price we pay for a General-purpose environment where resources are shared, protected, and abstracted.
This “meaningful complexity” is becoming even more critical in the era of AI and Software-Defined Vehicles (SDV). Look at NVIDIA CUDA. AI developers use the same PyTorch code for a GTX 1080 or an H100. This is only possible because the CUDA driver abstracts the hardware differences.
To truly master GPU and NPU utilization today, one must understand the driver layer. You don’t need to memorize every line of a GPU driver, but you must understand how requests flow through the kernel to know which metrics to monitor and how to manage bottlenecks.
In my own research, analyzing the Hailo NPU device driver and its interaction with the hailort library was the key to developing a Kubernetes Device Plugin that actually performs in real-time edge environments.
Ultimately, the ability to navigate this complexity is what separates a user of systems from an engineer who controls them. Whether it’s a single LED or a cluster of 1,000 NPU nodes, the fundamental principles of the OS remain the same.
In my next post, I’ll share how these kernel-level insights translate into orchestrating NPU resources within Kubernetes.