Lambda는 어떻게 EC2보다 5배 더 잘 벌까?
과거 초기 스타트업에서 개발할 당시, 저는 AWS Lambda를 자주 사용했습니다. 인프라 관리 수고가 거의 없고, 실행된 만큼만 비용을 지불하면 됐으니까요. 실제 스타트업에서 한 달에 수만 건의 요청을 처리해도 비용은 커피 몇 잔 값인 만 원을 넘지 않았습니다. 당시에는 “이렇게 싸게 팔아서 AWS는 남는 게 있나?“라는 막연한 의구심만 가졌습니다.
하지만 대학원에 와서 OS를 전공하며 가상화와 커널을 깊게 파고든 지금, 재무적 시각을 더해 다시 보니 놀라운 사실이 보였습니다. AWS Lambda는 사용자에게 저렴할 뿐만 아니라, 사실 AWS에게 EC2보다 훨씬 높은 마진을 가져다주는 효자 상품이라는 점입니다.
어떻게 이런 ‘윈-윈’ 구조가 가능한 걸까요? 그 핵심은 Utilization(평균 이용률)과 Firecracker라는 혁신적인 가상화 기술에 있습니다.
1. 이윤의 핵심: “놀고 있는 CPU를 되팔기” Link to heading
클라우드 사업자의 수익은 결국 ‘동일한 하드웨어에서 얼마나 많은 고객의 코드를 실행하느냐’에서 나옵니다. 일반적인 EC2(Virtual Machine) 모델은 고객에게 특정 코어와 메모리를 통째로 대여해 줍니다. 128개 코어, 256개 스레드가 있는 서버 CPU를 가정할 시, 이 스레드 한 개를 vCPU 1이라 보고 VM을 만드는 구조이죠. 이 서버 구조에선 vCPU 1개 기준 256개의 EC2를 만들고 최대 256명의 고객에게 제공할 수 있습니다.
이 부분도 자세히 들어가면 Overprovisioning 등 복잡해지지만, 편의상 vCPU 1개 = 1 EC2인 Dedicated model이라 가정하겠습니다.
하지만 문제는 고객이 이 자원을 100% 쓰지 않는다는 것입니다. CAST AI의 조사에 따르면, 기업들이 프로비저닝한 CPU의 평균 이용률(Utilization)은 고작 13%에 불과합니다. 이는 뒤집어 말하면 하루의 20시간을 CPU가 아무 일도 하지 않고 놀고 있다는 뜻입니다.
물론 클라우드 사업자는 vCPU 1개당 하나의 EC2 이용권을 고객에게 제공했지만, 만약 더 싼 가격에 1명이 아닌 수십, 수백명이 vCPU 1개를 교대로 쓰게 만들어 CPU를 더 굴린다면 어떨까요? (=Utilization을 높이기) 더 많은 돈을 받을 수도 있지 않을까요? 즉, 고객을 256명이 아닌 수만명으로 늘리는 것이죠. 물론 렌터카 사업이라면 차가 주차장에 서 있을 때 다른 손님에게 빌려줄 수 없지만, 소프트웨어의 세계에선 가상화 기술을 이용해 초단위로 자원을 회수하고 재할당함으로써 수익성을 극한으로 끌어올리는 것이 가능합니다. 그리고 이 모델이 Serverless로 이어집니다.
단순히 ‘이론적으로 더 많이 팔 수 있다’는 말을 넘어, 실제 AWS의 가격 정책을 통해 이 유휴 시간이 어떻게 막대한 이윤으로 치환되는지 계산해 보겠습니다.
산술적으로 비교해보는 수익성 (EC2 vs Lambda) Link to heading
AWS가 가진 ‘1GB 메모리’라는 동일한 물리적 자원을 1시간 동안 팔았을 때, 서비스 모델에 따라 매출이 어떻게 달라지는지 비교해 보겠습니다.
| 항목 | EC2 (t4g.micro) | Lambda (1GB 할당) |
|---|---|---|
| 시간당 고정 단가 | $0.0104 | $0.00 (호출 없으면 0원) |
| 1시간 풀 가동(Duration) | $0.0104 | $0.0600 ($0.0000166667 × 3600) |
| 요청 횟수 따른 비용 (변수) | $0.00 (무제한) | +$0.0007 ~ $0.0720 |
| 최종 매출 (AWS 관점) | $0.0104 | 약 $0.0607 ~ $0.1320 |
결과를 보면 동일한 자원을 1시간 동안 풀 가동하여 팔았을 때, Lambda의 매출($0.060)이 EC2($0.0104)보다 약 5.7배 높습니다. 그리고 이 같은 시간 동안 더 짧은 요청으로 인해 요청 횟수가 더 많다면 Lambda는 EC2대비 최대 12배의 이윤을 낼 수 있습니다. 이렇게 보면 고객 입장에선 Lambda를 쓰는 게 손해처럼 보이지만, 고객은 자신이 호출한 만큼의 비용만 결제하기 때문에 “싸다"고 느끼며 만족합니다. 앞서 말씀드린 것처럼 vCPU 1개를 빌려도 실상 회사는 CPU를 13% 밖에 못 쓰며 이미 손해를 보고 있었기 때문이죠.
2. 기술적 난제: “더 촘촘하게, 더 빠르게” Link to heading
하지만 이 ‘공유 경제’ 모델을 실현하려면 아주 까다로운 기술적 조건이 필요합니다. 수천, 수만 명의 코드를 한 대의 서버에서 돌리려면 다음 세 가지가 완벽해야 합니다.
- 격리(Isolation): 옆집 고객의 코드가 내 데이터에 접근하거나 호스트 시스템을 장악하면 안 됨 (보안).
- 최소한의 오버헤드: 가상화 계층이 너무 무거우면 자원 공유로 얻는 이득이 줄어듦.
- 빠른 프로비저닝: 요청이 들어오는 즉시 실행되어야 함 (수 초 내로, Cold Start 방지).
우리가 흔히 아는 기존 기술들은 여기서 한계에 부딪힙니다.
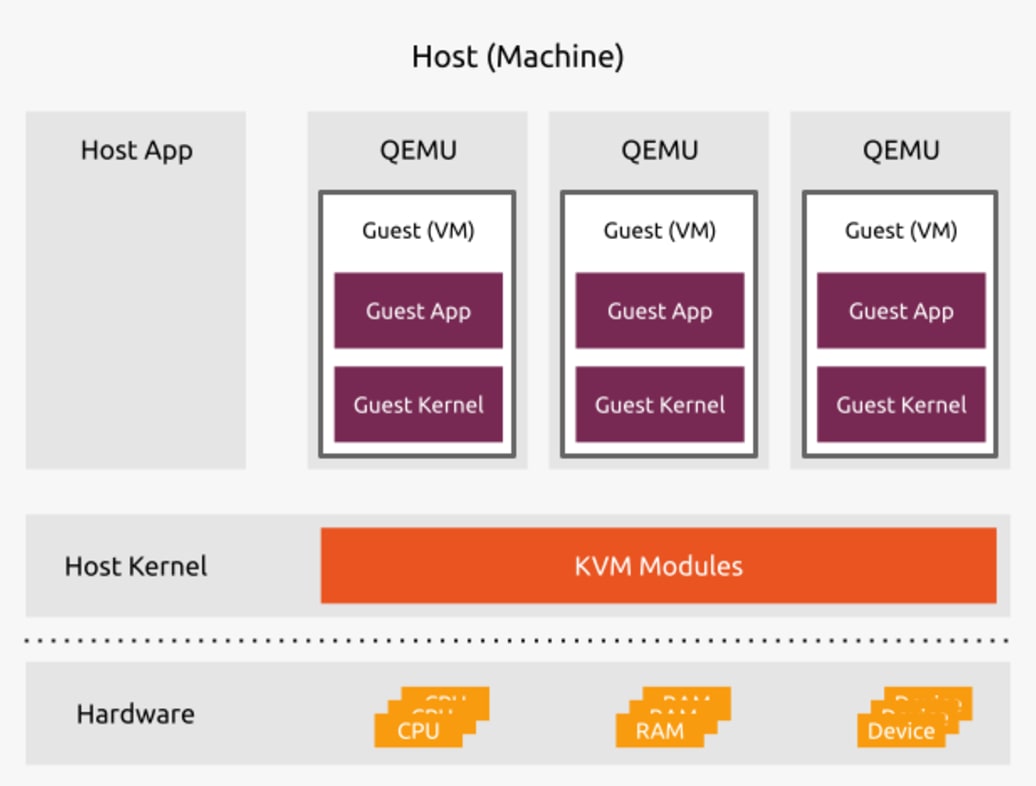 출처: Ubuntu 공식 블로그
출처: Ubuntu 공식 블로그
QEMU 기반 VM & KVM: KVM (Kernel-based Virtual Machine)은 리눅스 커널을 하이퍼바이저로 변신시켜주는 리눅스의 sub-system 중 하나입니다. 하드웨어 가속(VT-x)을 사용해 VM간 교체에는 문제가 없지만, 정작 QEMU가 디바이스(BIOS, Disk, Network 등)를 에뮬레이션하는 과정이 무겁습니다. 이 에뮬레이션 이후에 독립된 커널을 통째로 부팅해야 하므로 부팅에 수 초~수십 초가 걸립니다. EC2라면 상관없지만, 람다처럼 짧은 함수 실행에는 치명적인 오버헤드입니다.
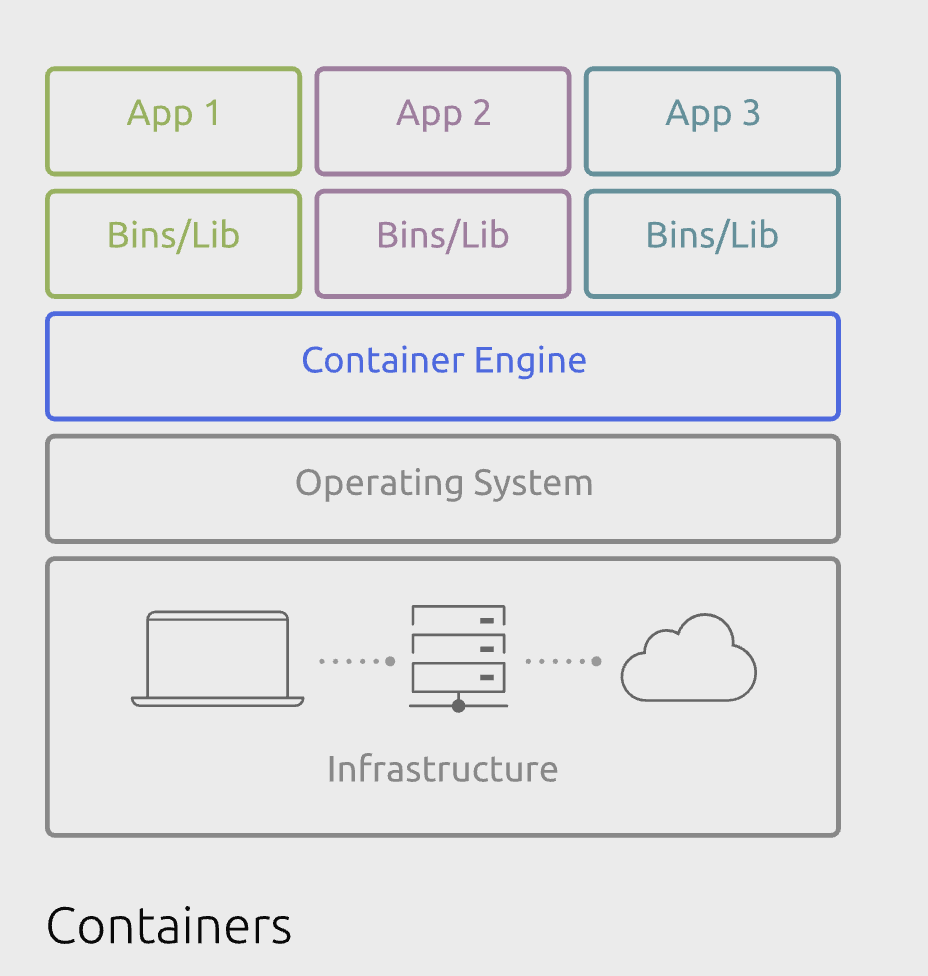
Container (Docker 등): Container는 리눅스의 Namespace(격리)와 Cgroups(자원 제한)를 활용하는 프로세스 레벨 가상화입니다. 별도의 커널 부팅 없이 호스트 커널을 공유하므로 실행 속도는 매우 빠르지만, 거꾸로 이 공유가 약점입니다. 특정 컨테이너에서 커널 취약점을 이용해 탈옥(Escape)에 성공하면, 같은 호스트의 다른 고객 데이터가 모두 노출됩니다. 멀티 테넌트 환경인 퍼블릭 클라우드에선 용납할 수 없는 리스크입니다.
3. 해답은 MicroVM, ‘Firecracker’ Link to heading
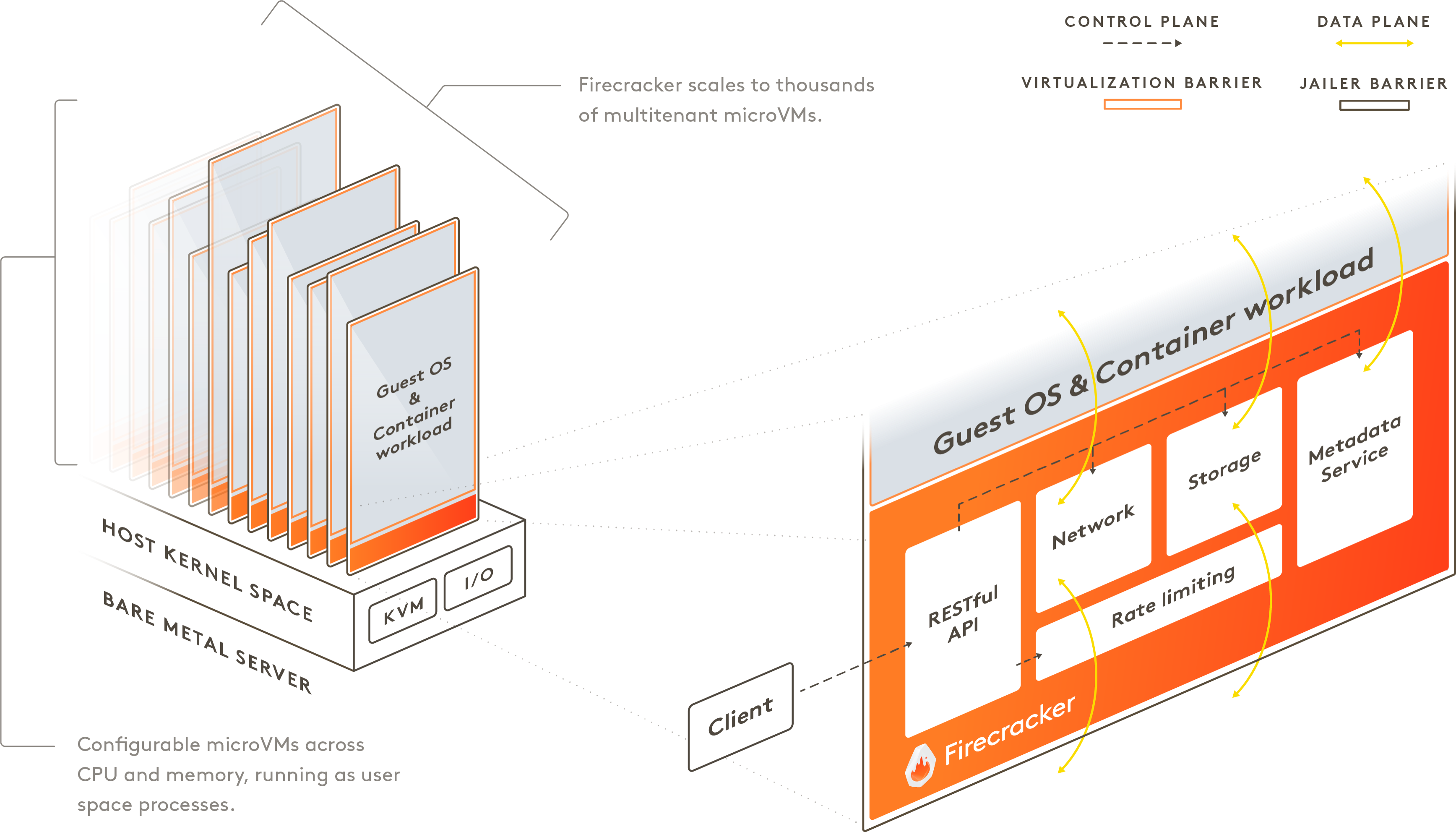 출처: https://firecracker-microvm.github.io/
출처: https://firecracker-microvm.github.io/
AWS는 이 간극을 메우기 위해 직접 Firecracker라는 MicroVM을 만들었습니다.
Firecracker는 QEMU처럼 KVM을 기반으로 하지만, 기존 QEMU에서 불필요한 장치(레거시 키보드 컨트롤러, 비디오 카드 등)를 모두 걷어내고 딱 필요한 것만 남긴 극도로 경량화된 가상화 기술입니다.
| 특징 | QEMU (Traditional VM) | Container | Firecracker (MicroVM) |
|---|---|---|---|
| 격리 수준 | 매우 높음 (HW 수준) | 낮음 (OS 수준 공유) | 높음 (MicroVM 수준) |
| 부팅 속도 | 수 초 ~ 분 | 밀리초(ms) | 125ms 미만 |
| 메모리 오버헤드 | 수백 MB 이상 | 매우 적음 | 약 5MB 이하 |
실제로 실험해 보면, Firecracker는 리눅스 커널을 부팅하는 데 단 0.1초(125ms) 내외면 충분합니다. 이는 1초에 수천 개의 독립된 가상 머신을 띄울 수 있다는 뜻이며, AWS가 고객의 요청이 올 때만 즉시 CPU 자원을 할당하고 다시 회수하는 ‘Utilization의 극대화’를 기술적으로 가능케 한 핵심 동력입니다.
결론: 시스템 엔지니어의 눈으로 본 서버리스 Link to heading
결국 AWS Lambda의 성공은 어떻게 하면 유휴 자원을 최소화할 것인가"라는 비즈니스적 질문에 대해, “MicroVM을 통한 초경량 가상화"라는 시스템 기술로 답한 결과물입니다.
사용자는 관리의 편의성을 얻고, 클라우드 사업자는 극강의 자원 효율성을 통해 높은 이윤을 창출합니다. 이 마법 같은 구조의 이면에는 리눅스 커널과 가상화 기술을 극한까지 깎아낸 엔지니어링의 정수가 숨어 있습니다.
그렇다면 여기서 또 다른 의문이 생깁니다. 이 글에서는 편의상 “vCPU 1개 = 물리 코어 1개"로 가정했지만, 실제로 VM은 물리 서버와 같은 것일까요? vCPU는 정말 우리만의 CPU일까요? 그리고 오버프로비저닝은 실제로 어떤 문제를 일으킬까요? 다음 글에서 이 구조를 더 깊게 파헤쳐 보겠습니다.