VM은 정말 서버 한 대일까?
클라우드에서 VM을 하나 생성하면, 우리는 그것을 “서버 한 대"처럼 다룬다. vCPU를 2개 선택하고 메모리를 할당하면, 몇 초 뒤에는 완전한 리눅스 머신이 SSH로 접속을 기다린다. 파일 시스템도 있고, 프로세스도 돌고, CPU 사용률도 보인다. 겉으로 보면 물리 서버와 다를 것이 없다.
그런데 실제로 그 VM 안에서는 무슨 일이 일어나고 있을까? 그리고 우리가 설정한 vCPU 2개, 메모리 4GB는 정말 우리 것인가?
결론부터 말하면 VM은 물리 서버가 아니다. VM은 Host Linux 위에서 실행되는 하나의 프로세스 집합이며, 내 VM은 다른 고객들의 VM과 물리적인 CPU 코어를 두고 서로 경쟁한다. 이로 인해 내 VM의 실행이 예상보다 늦어질 수 있으며, 10ms를 sleep 하는 단순한 기능 조차 30ms 이상의 오차를 만들 때도 있다.
이 글은 그 구조를 단계적으로 따라가 본다.
- VM이 실제로 무엇인지 — vCPU의 실체
- 클라우드가 오버프로비저닝을 할 수밖에 없는 이유
- 그 결과로 나타나는 steal time, scheduling latency, timer drift의 연쇄 반응
- 그리고 왜 이것이 real-time 시스템 관점에서 중요한 문제인지
이제 그 구조를 하나씩 내려가 보자.
VM의 정체: 서버가 아니라 프로세스 Link to heading
VM의 동작 원리를 이해하려면 먼저 하이퍼바이저(hypervisor)를 봐야 한다. 현재 대부분의 클라우드 환경, AWS를 포함한 주요 업체들은 **KVM (Kernel-based Virtual Machine)**을 기반으로 VM을 운용한다. KVM은 리눅스 커널 자체가 하이퍼바이저 역할을 하는 구조다. 즉, 물리 서버에서 동작하는 host Linux 위에 KVM 모듈이 올라가고, 그 위에서 여러 guest VM이 동시에 실행된다.
여기서 한 단계 더 내려가 보자. 우리가 콘솔에서 선택한 vCPU 2개는 물리 CPU 코어 2개가 아니다. KVM에서 vCPU는 host OS 입장에서 하나의 스레드로 표현된다. 내 VM의 vCPU가 연산을 수행한다는 것은, 결국 host Linux 스케줄러가 특정 물리 코어에 그 스레드를 잠시 올려 실행시킨다는 뜻이다.
이 사실은 곧바로 다음 질문으로 이어진다. 그렇다면 host가 바쁘다면? 다른 VM들이 동시에 CPU를 요구한다면? 그 순간 내 VM은 어떻게 될까?
왜 물리 코어보다 더 많은 vCPU를 팔 수 있을까 Link to heading
물리 서버 한 대에 코어가 64개 있다고 가정해보자. 클라우드 업체가 이 서버에 vCPU 2개짜리 VM만 32개를 올리면, 이론상 물리 코어와 vCPU 수가 정확히 일치한다. 하지만 실제 운영은 그렇게 단순하지 않다.
대부분의 VM은 항상 100%로 CPU를 사용하지 않는다. 웹 서버는 요청이 없을 때 idle 상태고, 배치 작업은 특정 시간대에만 부하가 몰린다. 클라우드 업체는 이런 통계적 특성을 기반으로 물리 코어보다 더 많은 vCPU를 판매한다. 64코어 서버에 총 128개 이상의 vCPU를 할당하는 것도 드문 일이 아니다. 이것이 오버프로비저닝이며, 이전 글에서 말했듯 오버프로비저닝을 많이 할수록 같은 물리적인 서버 하나를 가지고도 더 많은 돈을 벌 수 있다.
평소에는 문제가 드러나지 않는다. 하지만 같은 물리 서버 위의 VM들이 동시에 CPU를 강하게 사용하기 시작하면, host 스케줄러는 제한된 물리 코어를 두고 여러 vCPU 스레드를 번갈아 실행해야 한다. 이때부터 “내 VM은 왜 느려졌지?“라는 현상이 발생한다.
아래 그래프는 10시간 동안 Vultr과 AWS에서 측정한 steal time이다.
Vultr는 AWS 급은 아니지만 EC2와 같은 VM을 더 싼 가격에 제공하는 중형 클라우드 회사이다.
Steal time은 바로 뒤에서 설명하지만, 일단 내 VM이 host에게 뺏긴 시간이라고 보자.
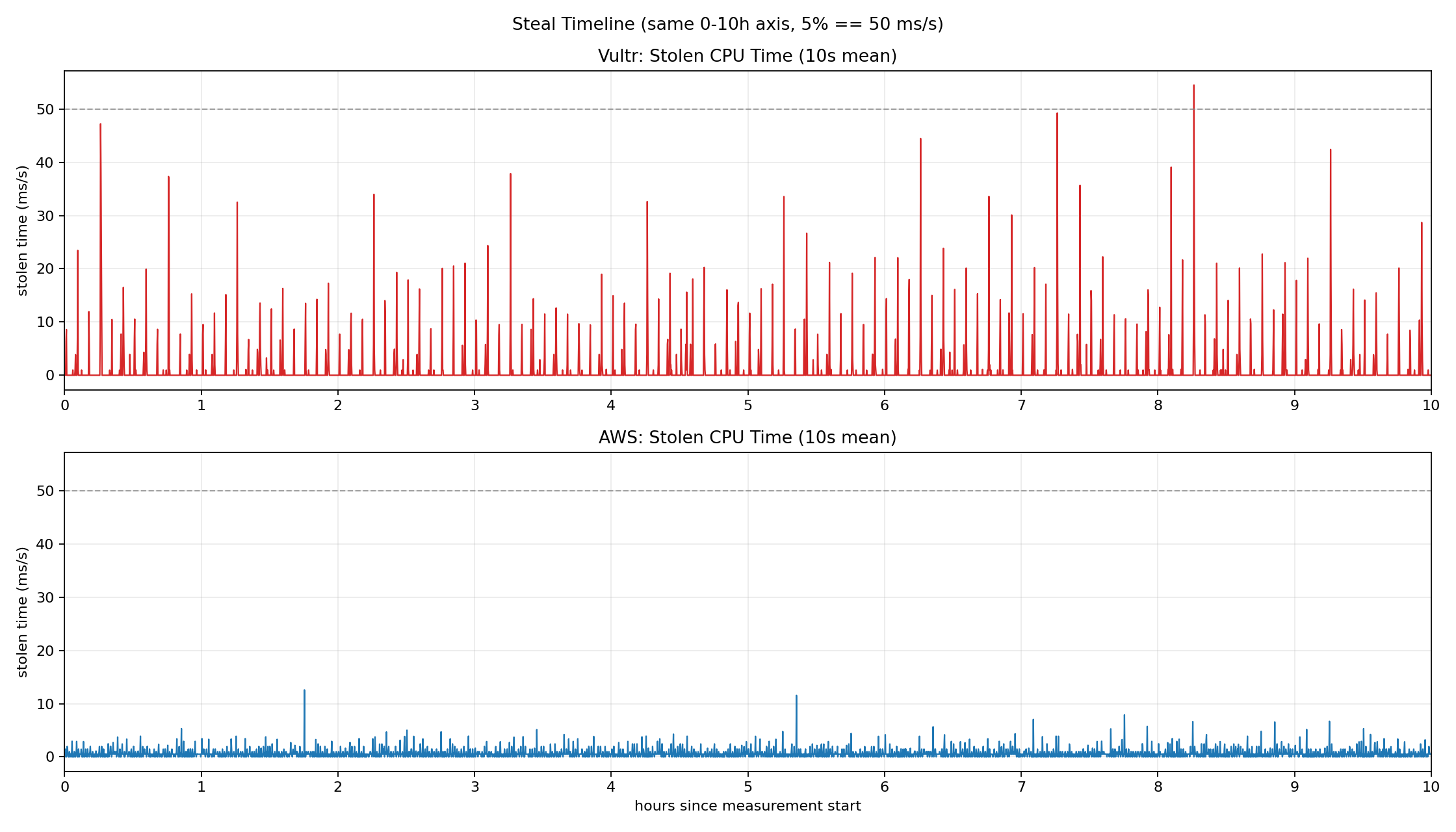
Vultr(빨간색)는 steal time이 수시로 20~40 ms/s를 넘기고, 피크 시에는 50 ms/s 선(5%)에 근접하거나 초과하는 구간도 보인다. AWS(파란색)는 클라우드 1위 회사 답게 steal time이 비교적 낮게 유지되지만, 간헐적으로 10 ms/s 이상의 스파이크가 발생한다. 두 환경 모두 steal time이 0으로 고정되어 있지 않으며, 그 발생 시점 역시 예측할 수 없다.
그래서 실제로 어떤 일이 벌어질까 Link to heading
이제 다시 처음의 10ms sleep으로 돌아가 보자. 왜 단순한 대기조차 정확히 지켜지지 않을까?
오버프로비저닝의 영향은 두 단계로 드러난다. 이들은 서로 독립적인 현상이 아니라, 하나의 인과 사슬로 이어진다.
① Steal Time — CPU를 빼앗기는 시간

top 명령어를 실행하면 CPU 사용률 항목 중 %st가 보인다. 이것이 steal time이다. 내 VM이 CPU를 사용하려 했지만, host가 다른 VM에 물리 코어를 할당하느라 기다려야 했던 시간의 비율이다.
예를 들어 1초 동안 50ms의 steal time이 기록되었다면, 그 50ms 동안 내 vCPU는 아무 일도 하지 못하고 대기한 셈이다. 애플리케이션 입장에서는 “느려진” 것이 아니라, 아예 실행 기회를 받지 못한 것이다.
② Timer Precision — 시간 자체가 흔들린다
이는 곧 타이머의 정밀함과 연결된다. 리눅스는 주기적인 타이머 인터럽트를 기반으로 스케줄링과 sleep을 처리한다. 그런데 이 인터럽트 역시 vCPU가 실제 물리 코어 위에서 실행 중이어야 정상적으로 처리된다.
steal time이 발생하는 구간에는 타이머 인터럽트 처리 자체가 지연된다. 그 결과 clock_nanosleep으로 10ms를 요청했음에도 실제로는 훨씬 더 지난 뒤에 프로세스가 깨어나는 현상이 발생한다. 아래는 이를 직접 측정한 timer drift 그래프다.
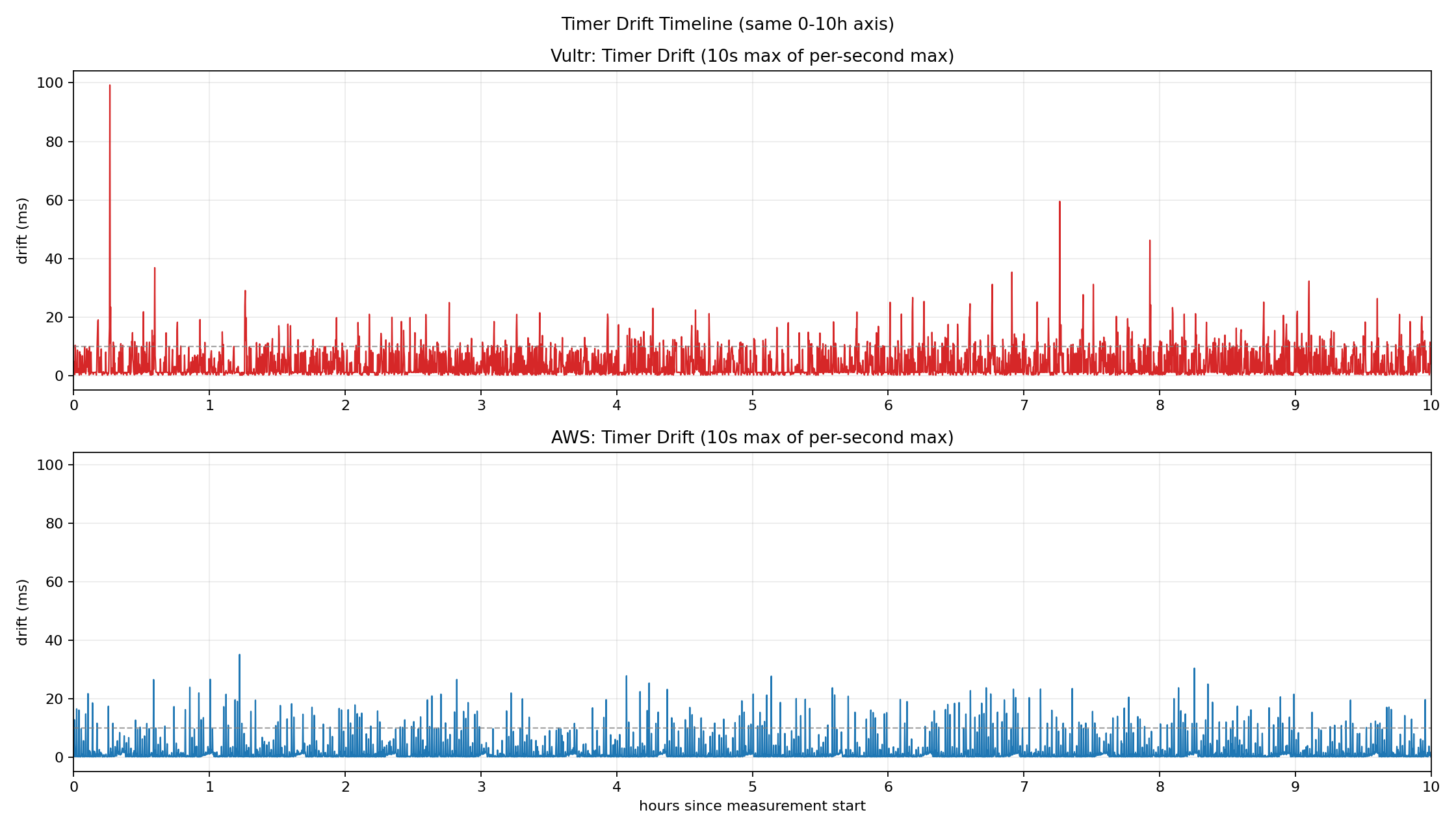
Vultr(빨간색)는 drift가 10ms 전후를 기본값처럼 유지하면서, 피크 시에는 100ms에 근접하는 구간도 나타난다. AWS(파란색)는 상대적으로 안정적이지만, 30ms를 넘기는 스파이크가 간헐적으로 관찰된다.
정리하면 다음과 같은 연쇄 반응이 일어난다.
오버프로비저닝 → steal time → 타이머 인터럽트 지연 -> guest 내 스케줄링 지연
결국 애플리케이션이 실제로 실행되는 순간은 가변적이며, VM 내부에서는 이를 완전히 통제할 수 없다.
어쩌다 발생하는 30ms 지연이 정말 문제일까 Link to heading
여기서 한 가지 질문이 남는다. 어쩌다 한 번 30ms 늦어지는 것이 그렇게 큰 문제일까?
사실 대부분의 웹 서비스나 일반 서버 워크로드에서는 그렇지 않다. API 응답이 가끔 수십 밀리초 늦어진다고 해서 사용자가 체감하지는 않는다. 회사 입장에서도 이런 변동은 모니터링 지표의 노이즈로 묻히는 경우가 많다. SLA 범위 안에만 들어오면 문제로 간주되지 않는다.
하지만 소프트웨어가 점점 더 물리 세계와 직접 연결되기 시작하면서 이야기는 달라진다. 예를 들어 원격으로 로봇을 제어해 수술을 한다고 가정해보자. 제어 신호가 수십 밀리초씩 지연된다면, 그것은 단순한 성능 저하가 아니라 사고로 이어질 수 있다. 차량 제어, 항공 시스템처럼 시간 제약이 본질적인 영역에서도 마찬가지다.
이처럼 “언제 실행될지"가 아니라 “반드시 언제까지 실행되어야 하는지"가 중요한 시스템을 real-time system이라 한다. 과거에는 주로 차량, 항공, 산업 제어 분야에서 연구되었지만, 최근에는 5G 코어 네트워크, telco cloud, 고빈도 트레이딩(HFT)처럼 클라우드 환경 위에서도 점점 더 중요해지고 있다.
리눅스 역시 이런 요구를 지원하기 위해 다양한 기능을 제공한다. SCHED_FIFO, SCHED_RR, SCHED_DEADLINE 같은 실시간 스케줄러가 존재하고, 최근에는 PREEMPT_RT 패치가 메인라인 커널에 통합되면서 커널 내부의 선점 지점을 더 정밀하게 제어할 수 있게 되었다.
문제는, 이런 스케줄러를 VM 안에서 사용하더라도 앞서 살펴본 오버프로비저닝 구조 위에서는 근본적인 한계가 존재한다는 점이다. guest 내부에서 아무리 높은 우선순위를 주더라도, host가 vCPU를 스케줄링하지 않으면 실행 자체가 불가능하다. 즉, real-time 정책은 guest 내부의 경쟁은 제어할 수 있지만, host 레벨의 경쟁까지는 통제하지 못한다.
물론 이런 민감한 요구사항을 가진 기업들은 이미 bare metal 인스턴스나 dedicated CPU 인스턴스를 활용하는 등 아키텍처 차원의 대응을 하고 있을 것이다. 그러나 개인이 만드는 프로젝트라 하더라도, 시간 제약이 중요한 시스템을 설계한다면 이 구조적 한계를 이해하는 것은 필수다.
이 지점에서 결론이 자연스럽게 이어진다.
마무리: 구조를 알고 선택하자 Link to heading
이 글에서 본 내용은 단순한 성능 튜닝 이야기가 아니다.VM이 어떻게 실행되는지, vCPU가 실제로 무엇인지, 그리고 오버프로비저닝이 어떤 연쇄 효과를 만드는지를 구조적으로 따라가 본 것이다.
웹 서버나 일반적인 백엔드 워크로드에서는 이러한 비결정성이 큰 문제가 되지 않을 수 있다. 그러나 시간 제약이 설계의 핵심이 되는 도메인 — 5G 인프라, 텔코 클라우드, 고빈도 트레이딩, 그리고 각종 제어 시스템 — 에서는 이 차이가 시스템의 성격을 바꿔버린다.
중요한 것은 “클라우드는 느리다"가 아니라, 클라우드는 공유 자원 위에서 동작한다는 사실을 전제로 설계해야 한다는 점이다.VM 위에서의 비결정성은 버그가 아니라 구조적 특성이다.
어떤 도메인에서는 이 특성을 받아들여도 된다.어떤 도메인에서는 아키텍처 선택부터 다시 고민해야 한다.
구조를 이해한 뒤에야, 그 선택이 가능하다.