Device Driver로 이해하는 OS의 추상화와 복잡성
간단해 보이는 것의 이면 Link to heading
대학원에 와서 OS를 본격적으로 공부하기 전, 임베디드 리눅스를 공부한다고 라즈베리파이로 LED를 제어를 해본 적이 있습니다. 브레드보드를 만진다고 귀찮았지만 코드 자체는 간단했습니다. Python 한 줄이면 충분했습니다.
|
|
대학원에서 OS를 공부하기 전까지, 저는 이 이상 생각해본 적이 없습니다. 하지만 OS를 공부하며 이 단순한 코드 뒤에는 system call과 device driver로 대변되는 거대한 추상화 계층을 알게 되었습니다. 이를 직접 구현하려면 수백 줄의 커널 코드가 필요합니다. 흥미로운 점은 Arduino 같은 베어메탈 환경에서는 이런 복잡성이 필요 없다는 것입니다. LED 제어가 OS 위에서는 왜 이렇게 어려운 걸까요? 그리고 이 복잡성은 왜 생긴 걸까요?
Device Driver의 본질: OS 자체가 문제다 Link to heading
Device driver는 운영체제가 디바이스를 직접 제어하기 위한 코드입니다. 여기서 디바이스라고 말하는 건 CPU, 메모리를 제외한, 컴퓨터에 연결되는 주변 기기들입니다. 하지만 단순히 “디바이스 접근 코드"라고 이해하면 본질을 놓치게 됩니다. Driver의 복잡성은 디바이스 자체보다는 그것이 동작하는 OS 환경의 구조적 특성에서 비롯됩니다. OS 환경은 세 가지 근본적인 특성을 갖습니다.
- 멀티태스킹: 수십 개의 프로세스가 동시에 실행되는 환경입니다.
- 보호: 잘못된 프로세스가 다른 프로세스에 접근 혹은 시스템 전체를 망가뜨리지 못하도록 하는 메커니즘이 필요합니다.
- 추상화: 동일한 인터페이스로 다양한 디바이스를 제어할 수 있는 추상화 계층이 요구됩니다.
이 세 가지 요구사항이 커널 공간(Kernel space)과 유저 공간(User space)의 분리를 만들어냅니다. 우리가 작성하는 일반적인 application은 보통 유저 공간에서 실행되며 CPU를 통한 연산 이외 디바이스에 직접 접근할 수 없습니다. JSON 파일을 읽고 쓰는 것, 네트워크 패킷을 보내는 것, 화면에 픽셀을 그리는 것 모두 특권을 가진 누군가에게 요청하는 방식으로 이루어집니다.
우리는 이런 요청을 **시스템 콜(System Call)**이라 부릅니다. 시스템 콜은 웹 개발자들이 자주 보는 REST API와 크게 다르지 않습니다. Kernel은 system call이라는 인터페이스를 노출하며, 애플리케이션이 이를 호출하면 CPU 모드가 커널 모드로 전환된 뒤에, kernel 내부에 구현된 핸들러가 실행됩니다.
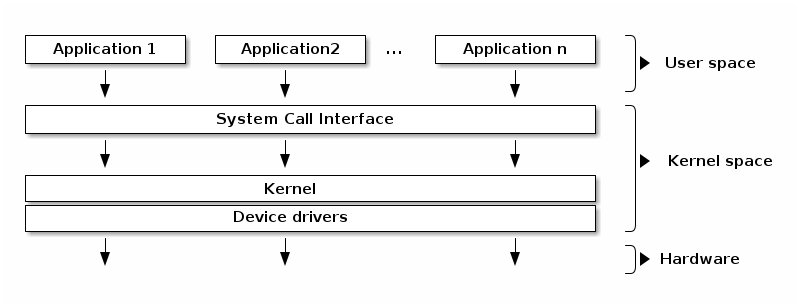
Figure 1: System Call Flow from User Space to Device Driver
사실 이 흐름도 Kernel 종류에 따라 다를 수 있지만, 앞으로의 설명은 Linux Kernel처럼 Monolithic Kernel을 가정하겠습니다.
Kernel 자체는 SSD, GPU, 네트워크 카드 등을 어떻게 제어해야 할지 본질적으로 알지 못합니다. 하드웨어 제조사가 “사용 설명서"를 제공해야 하는데, 이것이 바로 Device Driver입니다. 표준화를 위해 Linux는 이러한 드라이버를 파일 시스템을 통해 노출합니다.
*“Everything is a file”*이라는 말을 들어보셨을 겁니다. NVIDIA 드라이버를 설치하면 GPU가 /dev/nvidia0로 나타납니다. 그러면 일반적인 파일처럼 open(), read() 등의 명령(실제로는 시스템 콜)을 통해 GPU와 상호작용할 수 있습니다. 이 추상화 덕분에 복잡한 하드웨어를 익숙한 인터페이스로 관리할 수 있습니다.
Figure 1이 바로 이 인터페이스를 보여줍니다. 애플리케이션이 요청을 하면—LED를 켜든, 디스크를 읽든, 네트워크 데이터를 보내든—그 요청은 System Call Interface 경계를 넘습니다. CPU는 user mode에서 kernel mode로 전환되고, 적절한 Device Driver를 통해 요청을 라우팅한 후, 최종적으로 하드웨어 작업을 수행합니다.
실제 구현: Python 스크립트를 넘어서 Link to heading
시스템 수준에서 LED를 제어하려면, 실제로 두 개의 프로그램을 작성해야 합니다: Device Driver(브리지)와 Application(사용자).
기본적인 LED 드라이버 구조는 C로 다음과 같이 작성됩니다:
|
|
왜 이렇게 많은 “boilerplate"가 필요할까요?
copy_from_user(): User Space와 Kernel Space가 서로 다른 가상 메모리 주소 공간을 사용하기 때문에, 커널은 단순히 유저 공간 포인터를 역참조할 수 없습니다. 안전을 위해 데이터를 명시적으로 복사해야 합니다.spin_lock(): OS는 멀티태스킹 환경이기 때문에, 두 프로세스가 동시에 LED를 토글하려 할 수 있습니다. 락이 없으면 하드웨어 상태가 예측 불가능해집니다.
드라이버가 등록되면, “Application"은 셸 스크립트만큼 간단할 수 있습니다:
|
|
이 셸 스크립트를 통해 LED가 켜지거나 깜빡이는 것을 확인할 수 있습니다.
비동기 세계의 복잡성: 인터럽트 Link to heading
위 예제는 동기적 작업(프로세스가 액션을 시작)만 다룹니다. 하지만 하드웨어는 종종 비동기적입니다. 키보드나 네트워크 카드를 생각해보세요. 하드웨어가 이벤트가 발생했을 때 CPU에 알립니다. 이것이 바로 **인터럽트(Interrupt)**입니다.
수십 개의 프로세스를 스케줄링하는 OS에서는 하나의 프로세스가 하드웨어를 “폴링”(업데이트를 확인하기 위해 계속 루프)할 수 없습니다. 이는 CPU 사이클을 낭비하기 때문입니다. 대신 프로세스는 슬립 상태로 들어가고, 인터럽트가 프로세스를 “깨웁니다”.
LED 회로에 버튼을 추가하여 상태를 토글한다면, 인터럽트 핸들러가 필요합니다:
|
|
사실 이 부분도 엄밀히 본다면
gpio_set_value()함수는 여기서 쓰이는 게 아니라 워크큐에서 써하지만, 인터럽태 핸들러를 자세히 보는 게 목적은 아니니까 이 부분도 넘어가겠습니다.
이 부분만 보면 크게 어려울 건 없습니다. 대신 이렇게 인터럽트 처리를 해야하는 순간 인터럽트 핸들러 보다는 led_write()의 spin_lock()이 spin_lock_irqsave() 으로 바뀐다는 점이 중요합니다. 그 이유는 다음과 같습니다.
인터럽트 처리는 CPU가 여러 가지를 동시에 처리합니다. 네트워크 요청이 도착했을 시, 키보드나 마우스를 움직일 때, 다른 task로의 스위칭을 하기 위한 타이머 인터럽트 등등 여러 가지를 말이죠. 하지만 만약 led_write()이 spin_lock()으로 lock을 잡고 있을 때 인터럽트 핸들러 파트에서 led_lock을 잡으려 한다면 핸들러는 락이 해제되기를 기다립니다. 하지만 앞서 말했듯이 인터럽트 컨텍스트는 다른 핸들러들이 다 공유하며, 특히 타이머 인터럽트가 발생해야 다른 프로세스로 스위칭이 가능합니다. 그런데 지금은 인터럽트 핸들러가 계속 락을 잡으려 하지 종료되지 않기에 스위칭이 불가능하고, 거꾸로 스위칭이 되어야 led_write() 함수가 종료됩니다. 이는 전형적인 데드락 상황입니다.
따라서 led_write() 함수에서 인터럽트를 비활성화한 뒤 락을 잡도록 spin_lock_irqsave()로 바꿔줘야 하며, device driver 코드는 인터럽트 발생 여부에 따라 더욱 신중하게 작성되어야 합니다.
결론: 복잡성은 오케스트레이션의 기초 Link to heading
device driver의 복잡성은 “불필요한 것"이 아닙니다. 이는 자원이 공유되고, 보호되며, 추상화되는 범용 환경을 위해 우리가 치르는 대가입니다.
이 “의미 있는 복잡성"은 AI와 소프트웨어 정의 차량(SDV) 시대에 더욱 중요해지고 있습니다. NVIDIA CUDA를 생각해보세요. AI 개발자는 GTX 1080이든 H100이든 동일한 PyTorch 코드를 사용합니다. 이는 CUDA 드라이버가 하드웨어 차이를 추상화하기 때문에 가능합니다.
오늘날 GPU와 NPU 활용을 진정으로 마스터하려면 드라이버 계층을 이해해야 합니다. GPU 드라이버의 모든 줄을 외울 필요는 없지만, 요청이 커널을 통해 어떻게 흐르는지 이해해야 어떤 메트릭을 모니터링하고 병목 현상을 관리하는 방법을 알 수 있습니다.
제 연구에서도 Hailo NPU device driver와 hailort 라이브러리의 상호작용을 분석하는 것이 실시간 엣지 환경에서 실제로 작동하는 Kubernetes Device Plugin을 개발하는 열쇠였습니다.
궁극적으로 이 복잡성을 다루는 능력이야말로 시스템의 사용자와 시스템을 제어하는 엔지니어를 구분하는 것입니다. 단일 LED든 1,000개의 NPU 노드 클러스터든, OS의 근본 원리는 동일합니다.
다음 글에서는 이러한 커널 수준의 인사이트가 어떻게 Kubernetes 내에서 NPU 리소스를 오케스트레이션하는 것으로 전환되는지 공유하겠습니다.